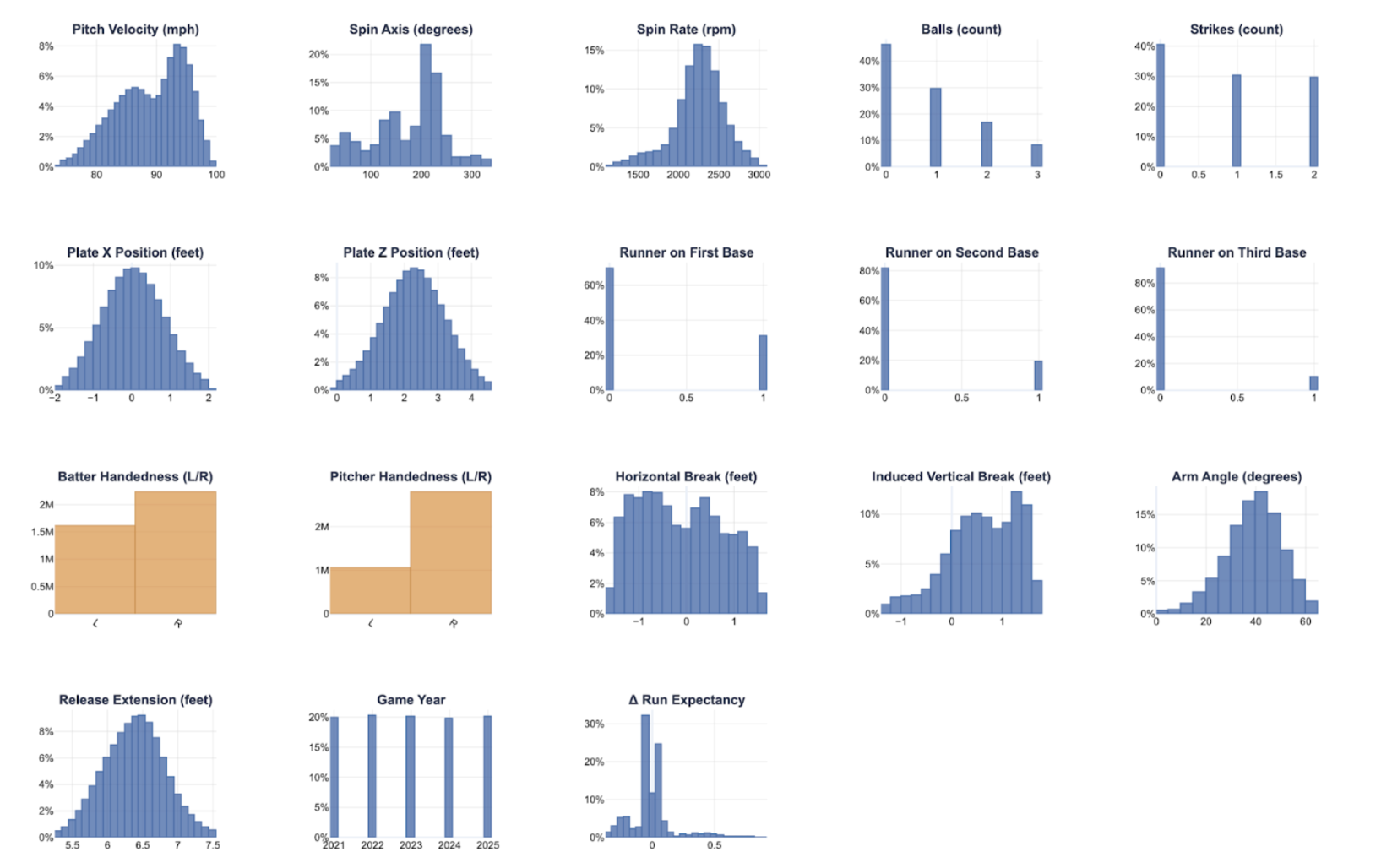
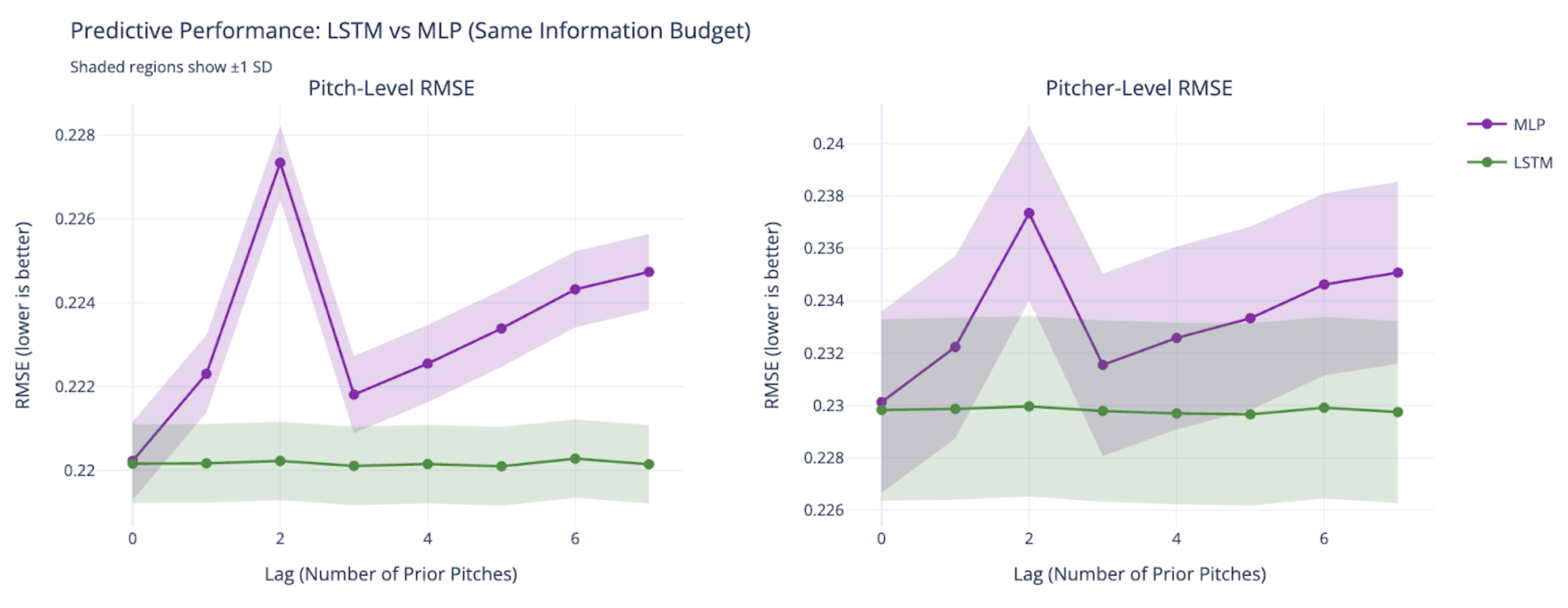
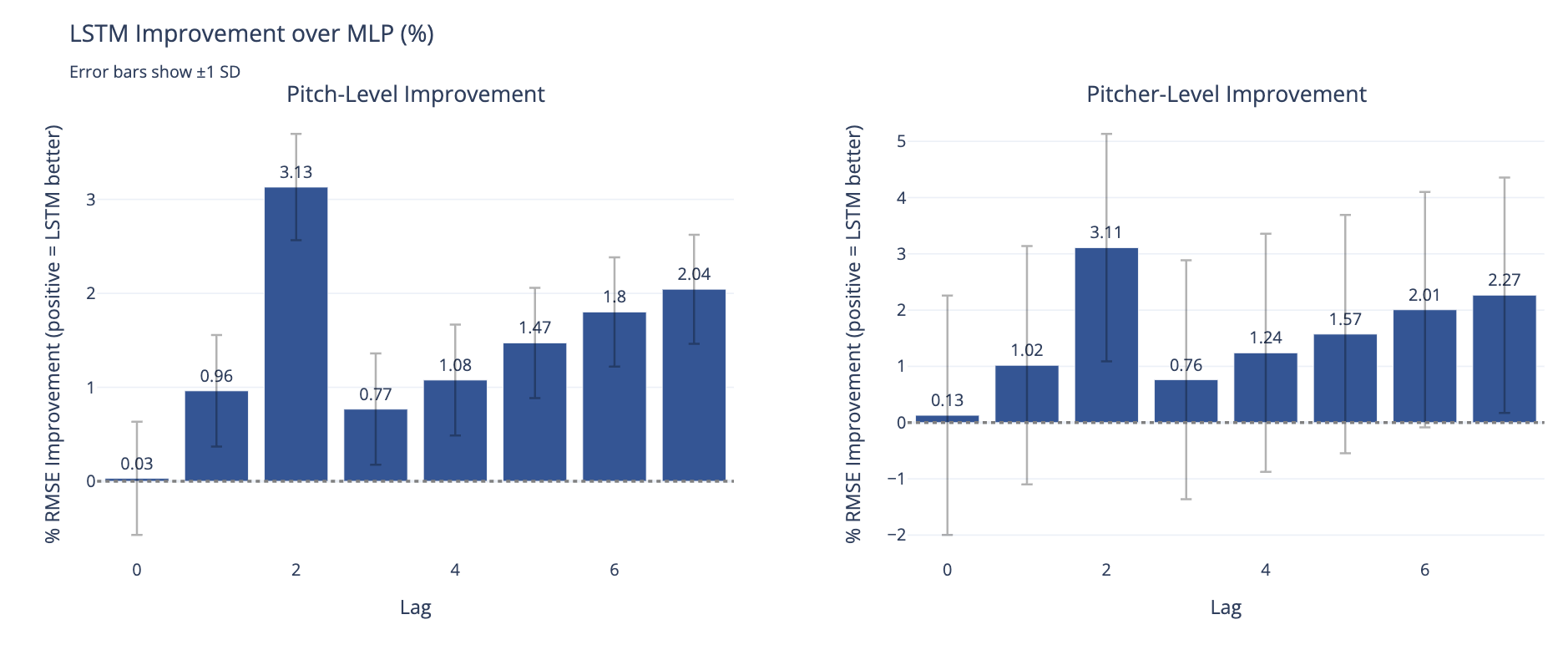
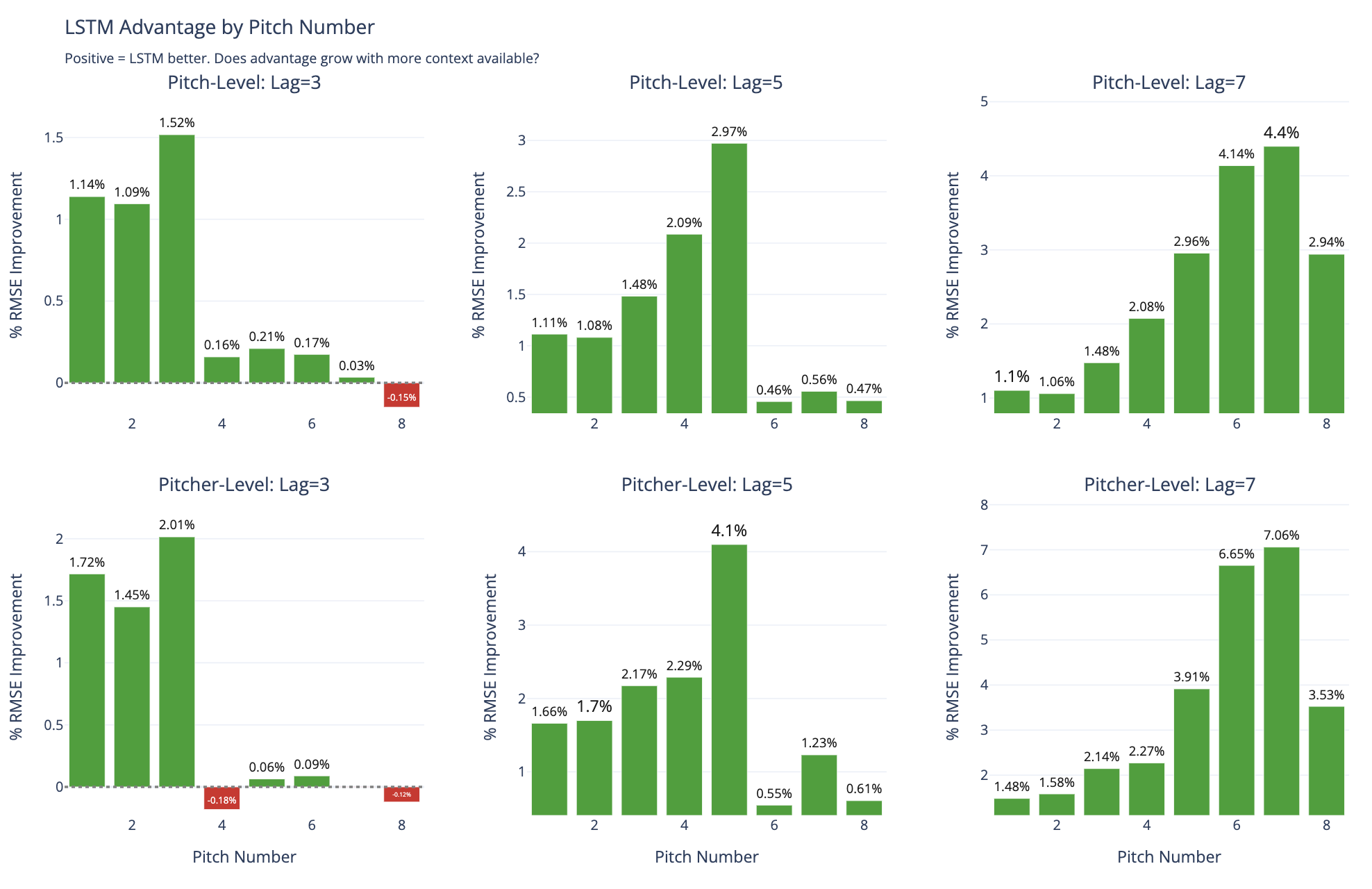
| Temporal Context in Deep Nets for MLB Pitch Modeling: A Study of Lag Length and Architecture | |||
| Henry Wang | |||
| Final project for 6.7960, MIT | |||
Background & Related Work
Sabermetrics, or baseball analytics, is the practice of applying scientific and mathematical principles to the game of baseball. This field, popularized by the film Moneyball, has become a mainstram practice in the sport. Every year, over 700,000 pitches are thrown in Major League Baseball (MLB), each being meticulously tracked by a wide array of technologies. Various optical and radar-based tracking systems allow analysts to build quantitative models using characteristics such as velocity, spin rate, and magnus-induced movement to characterize what makes pitches successful (by preventing runs).The science of pitch modeling, in particular, has become a mainstream practice in the sabermetrics community. The goal of pitch modeling is to use information of pitches (release speed, trajectory, spin, etc.) to predict a run value, where allowing less runs is favorable for the pitcher. Existing work in this space has revealed key insights that inform player development and evaluation strategies used today. For example, pitch models (oftentimes referred to as Stuff+ models) suggest that higher velocity on fastballs predict better outcomes for the pitcher, which has transformed the way pitchers train and develop.
Run Expectancy
Pitch modeling, in its simplest form, treats each pitch as a regression problem with a continuous target (a run-based value) and a set of pitch characteristics as inputs, such as velocity, spin rate, and so forth [5, 6]. To understand the concept of run values, it is useful to think of a baseball game as a Markov chain, where states are combinations of baserunner configurations (are there runners on 1st, 2nd, and/or 3rd) and the number of outs (0, 1, or 2). There are \(2^3 = 8\) possible baserunner states and 3 possible out states, resulting in \(8 \times 3 = 24\) base–out states. The expected number of runs scored from a given base–out state to the end of the inning is called the run expectancy.
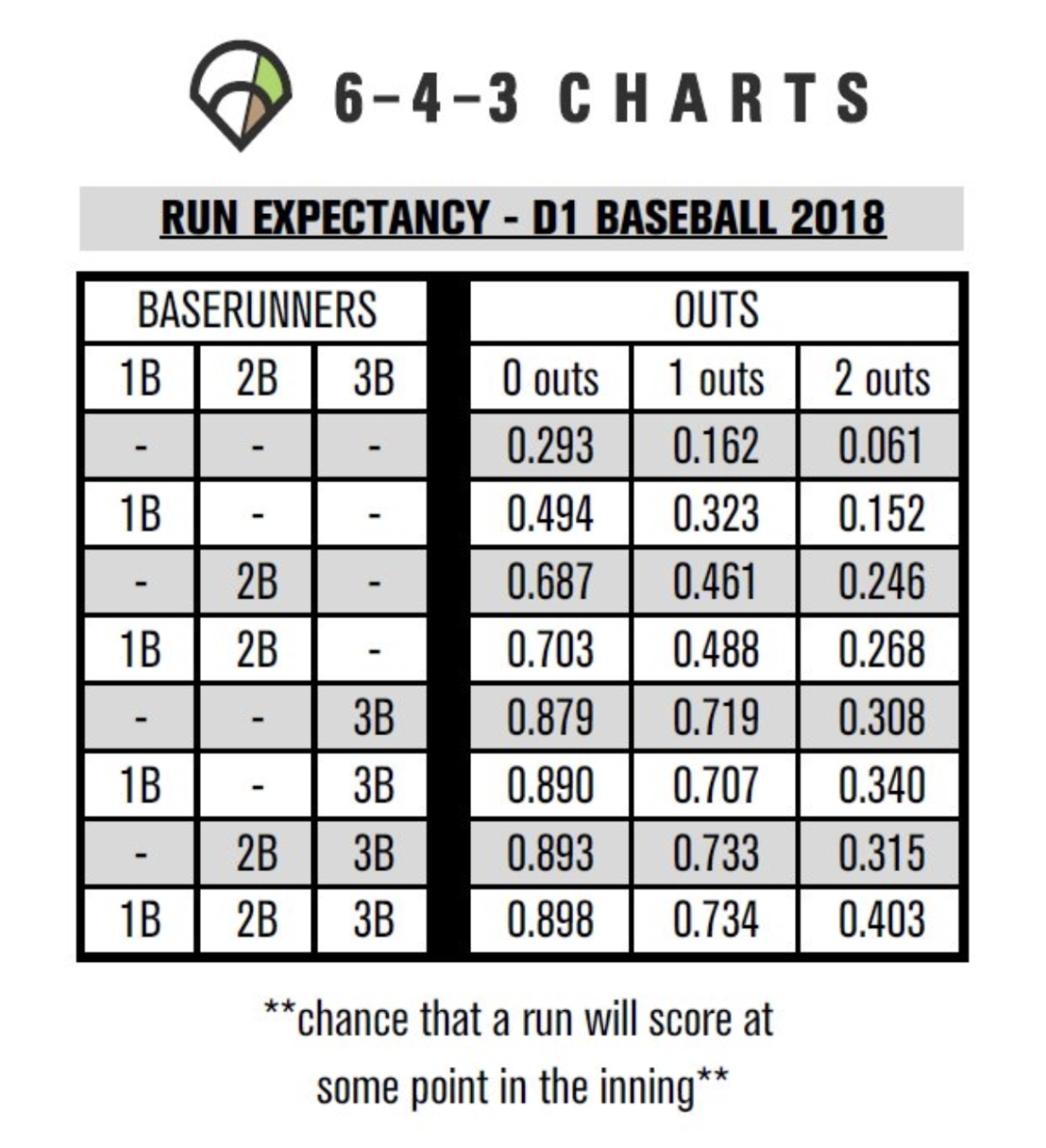
Figure 1. Example Run Expectancy Matrix for D1 Baseball 2018. The table shows the expected number of runs that will score from each base-out state to the end of the inning. Source: 6-4-3 Charts
Run expectancy can be defined more granularly using base–out–count states: this is the same idea as base–out states, except now we also condition on the ball–strike count. In full, there are 12 possible ball–strike counts, yielding \(24 \times 12 = 288\) base–out–count states.
Every pitch moves the game from one base–out–count state to another, each with its own run expectancy. The pitcher's goal is to reduce the overall run expectancy. The target we use is delta run expectancy (\(\Delta RE\)), meaning the change in run expectancy from before to after the pitch. This provides a numerical representation of the pitch's effectiveness at preventing runs.
As Figure 1 shows, the expected number of runs varies dramatically depending on the game situation. The formula for delta run expectancy is:
\[
\Delta RE = RE_{\text{after}} - RE_{\text{before}} + \text{Runs Scored on the Pitch}
\]
As a concrete example, consider the following scenario: A relief pitcher enters the game with the bases loaded and one out. They allow a sacrifice fly to score the runner from third, with the other two runners not advancing.
- Before: Runners on 1B, 2B, 3B; 1 out (RE = 0.734)
- After: 1 run scored; Runners on 1B, 2B; 2 outs (RE = 0.268)
- Delta RE: 0.734 - 0.268 + 1 = 1.466